Deep Dive Into Pytorch - Dataset and DataLoaders
When I started learning Pytorch, one of the most confusing things to me was the torch.utils.data.Dataset and torch.utils.data.DataLoader. There were certain rules to define these things and I always wondered what was going on behind the scenes or what would I need to do if I ever had to define a custom variation of them. Later when I learned about collate_fn, Sampler I started to understand the inner workings of how these are implemented. In this article, I want to dig deeper and understand from a fundamental level how these things work. Well, obviously there needs to be some level of abstraction, so when I say fundamental level, take it with a grain of salt.
What is a Dataset?
This might be surprising, but depending on your problem definition, it can be literally anything. For example, if you are doing a supervised object classification problem, a single data point in your dataset will contain an image and a label. Same thing if you are working with a tabular dataset and a label. One single data point is just one row in the table. These are the most basic examples and are straightforward to implement. But if you are doing something a little more complicated like working with a graph neural network, instead of an image it will contain a graph and the corresponding label. But to represent a graph you need two pieces of information. One is the feature matrix and the second is the adjacency matrix or edge list. This means now a single data point contains three “entities”. The feature matrix, graph connectivity information and label.
So, it is futile to concretely say what a dataset is. Hence, we need to show it in an abstract format.
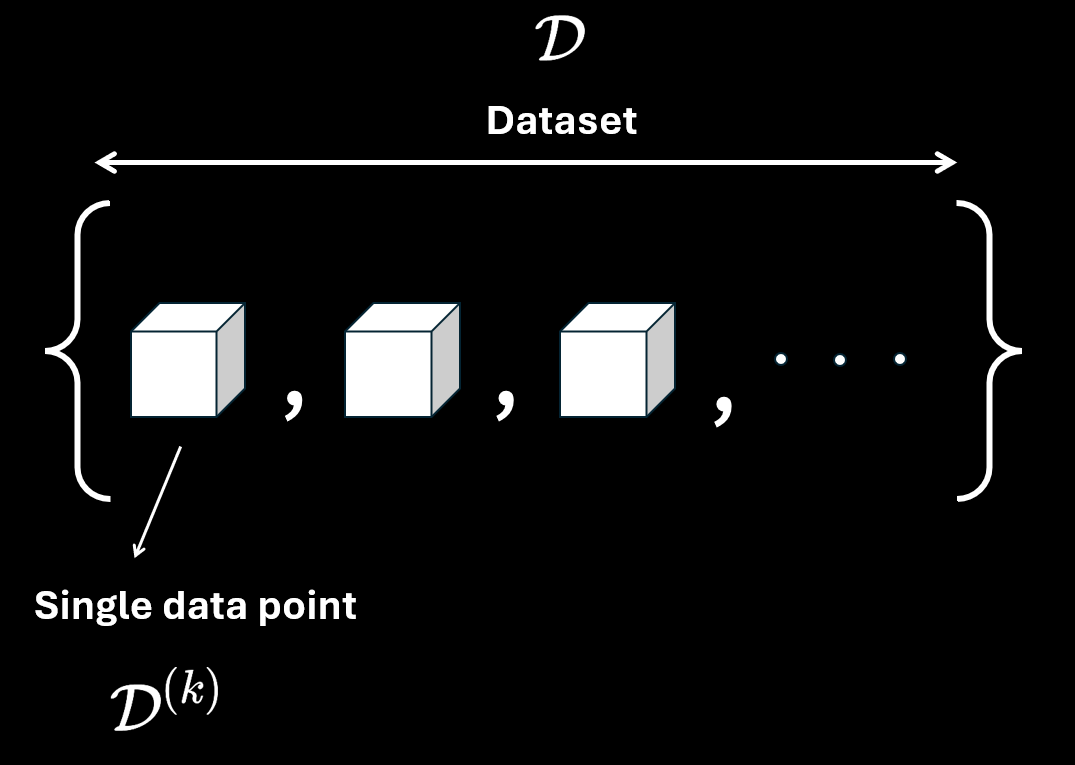
In the above diagram, I use white blocks to represent a single data point. Mathematically the entire dataset is represented by $\mathcal{D}$ and a single data point is represented by $\mathcal{D}^{(k)}$ where $k$ is the index.
You will notice I used curly braces to contain all the data points. This is to imply it is a set of data points. This implicitly means the order doesn’t matter which might not be true for certain cases like working time series or sequence data. But for simplicity, we will ignore those cases and assume the order does not matter.
Getting an appreciation for the abstraction
Let’s see some special cases to appreciate the need for abstraction.
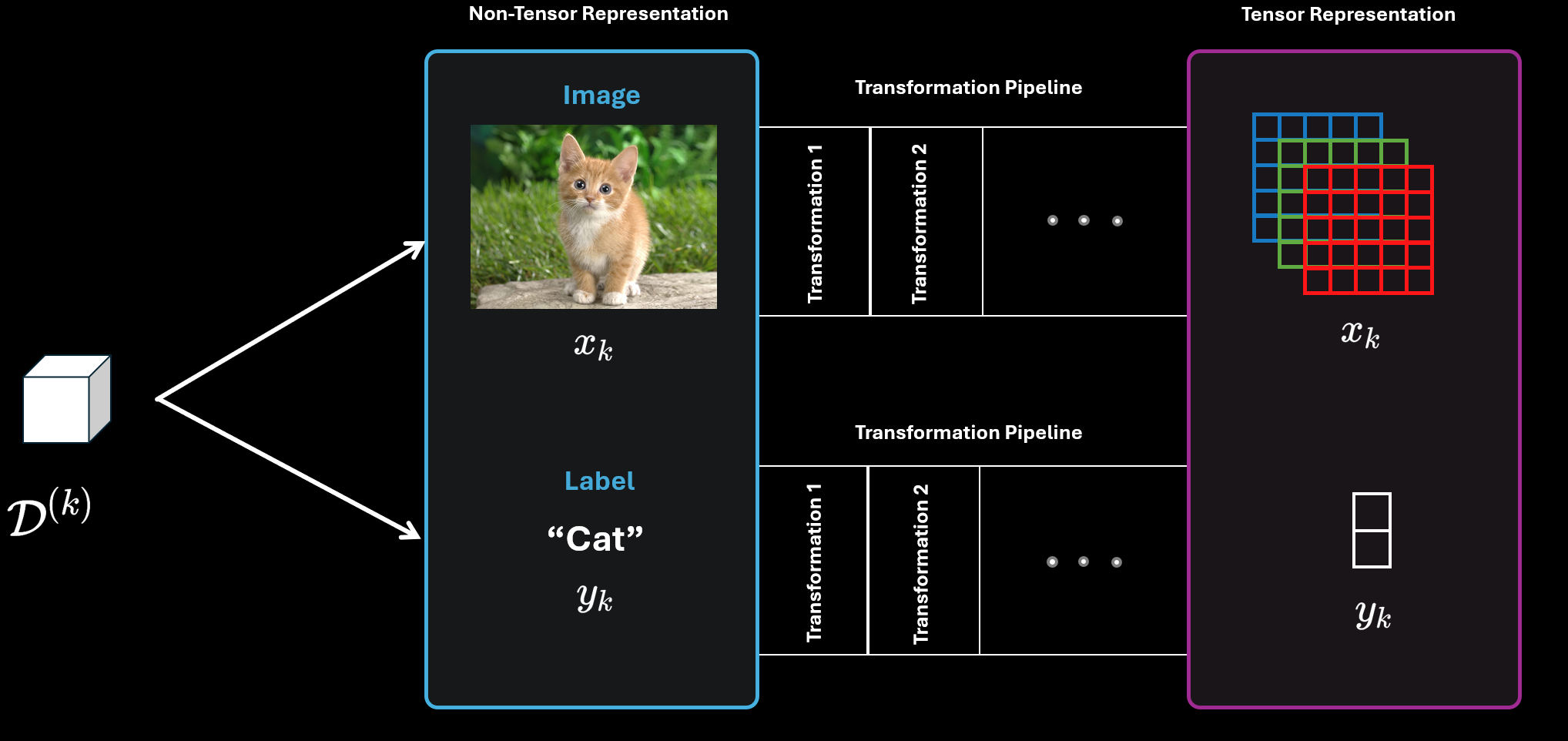
As an example consider the above case which is a supervised object classification problem. One single data point $D^{(k)}$ contains two “entities”. The first one is the image (denoted by $x_k$) and the second one is the label (denoted by $y_k$). However, both of them need to go through several transformations to get a tensor representation. These transformations can include normalization, changing the data type, cropping, scaling, etc. For image domain problems, torchvision provides several built-in approaches for transformation. In my experience, these are not enough and often you need to write custom transformations.
Let’s look at another special case where in addition to object classification, an additional task is object detection. For that, in addition to the classification label you need to provide the ground truth label for the bounding box of the object.
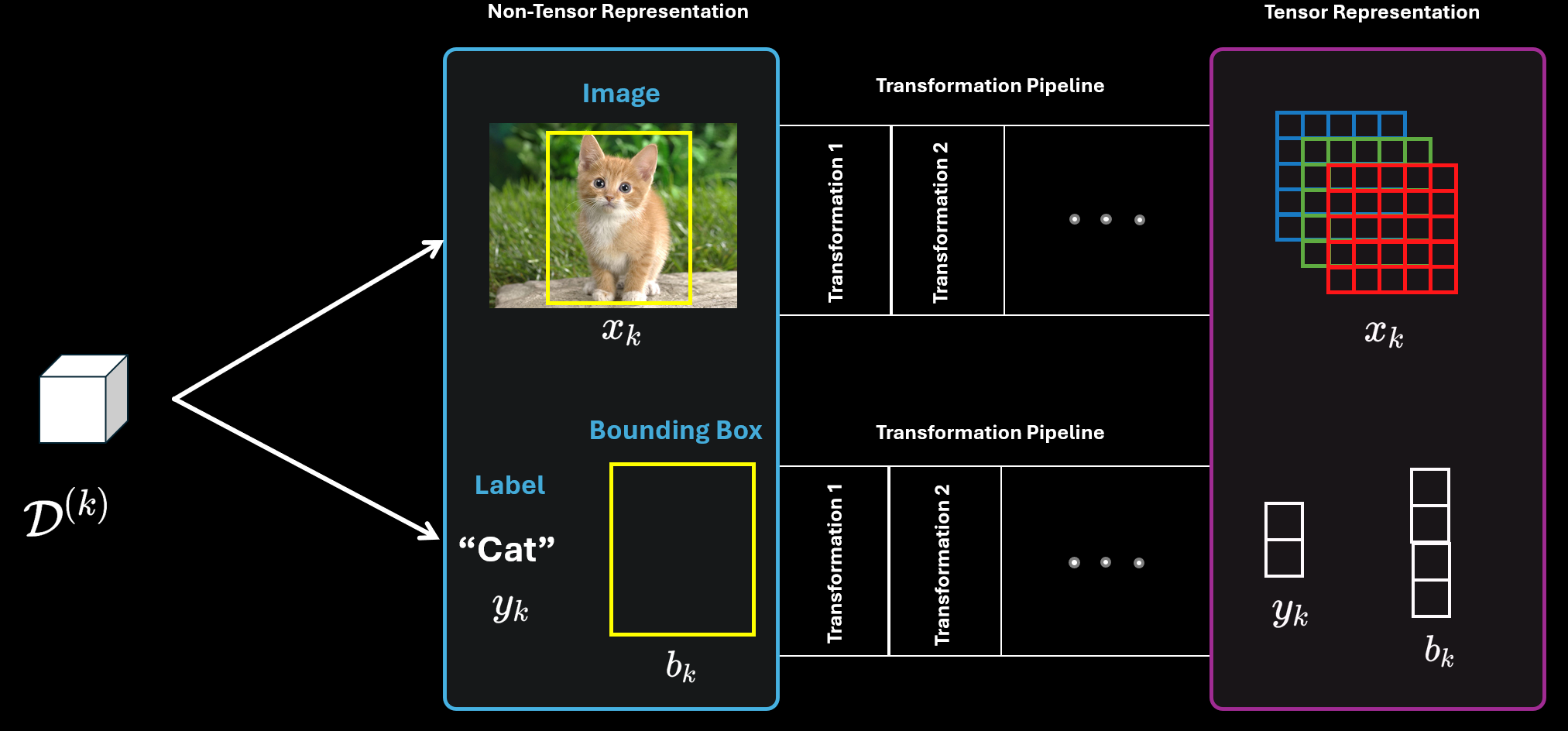
In this case, the dataset consists of three entities. The original image $x_k$, the classification label $y_k$ and the bounding box label $b_k$ for object detection.
Another such example is from a graph neural network. In the following example, $x_k$ consists of two parts $f_k$ which is the feature matrix and $e_k$ which is the edge matrix.
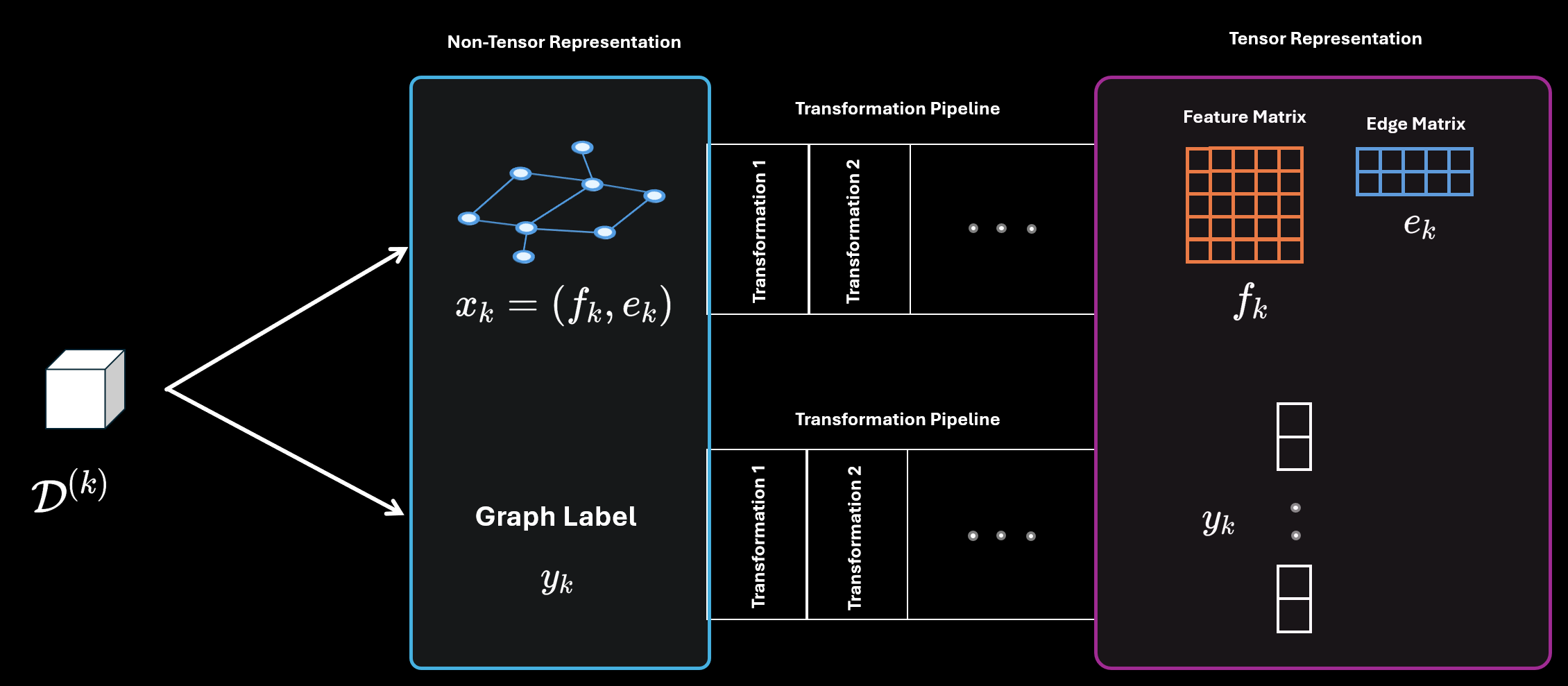
Based on these examples, it is easy to see the need for abstraction. There are just way too many ways a dataset can be formed. But as long as you follow certain criteria when defining your dataset, it does not matter what your dataset looks like.
torch.utils.data.Dataset
This is an abstract class provided in Pytorch for a map-style dataset. This can be used by subclassing it to create a custom dataset wrapper class.
The most basic version is shown below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, data, labels):
self.data = data
self.labels = labels
def __len__(self):
return len(self.data)
def __getitem__(self, index):
x = self.data[index]
y = self.labels[index]
return x, y
There are three dunder methods you can define.
__init__: This should take in all the data ‘entities’ in some form in addition to other optional things you might require. Or you can take in the file path to the dataset as an argument and perform loading and all the other stuff inside the__init__method. One common thing is passing in additional information like atransforms.compose()object.__len__: This method should return the length of the dataset. You can just use thelenfunction if all your data point is contained in a sequence. The most usual approach I have seen is all the data points are in a list. Or, it is a tabular dataset and just returningdata.shape[0]does the job. Note that, there are many cases where you might indirectly get the length of your dataset. For example, when you are reading images from a folder you can apply thelenfunction on top ofos.listdirto get the dataset length. You do not need to read all the images and store them in a list. So, it is possible to come up with innovative ways to return the total length of your dataset. But why do we need to define this? The most obvious reason is for theDataLoaderclass to work. When DataLoader performs batching it needs to know the length of the dataset. In addition, for shuffling or splitting the dataset you need to know the length.__getitem__: This needs to define the logic for how to access a single data point from the dataset and return the data ‘entities’. Again this can customized. I have seen applying transformations before returning the data ‘entities’.
How do you apply the transformations? If you are not doing something exotic, Pytorch provides some handy built-in transformations through torchvision.transforms for image data.
Applying transformations
Look up the official documentation image transformation for this as well the examples. There is a plethora of image transformations you can use. Pytorch provides transforms.Compose() to chain together multiple transformations.
A basic version from the Pytorch documentation :
1
2
3
4
5
6
7
8
9
from torchvision.transforms import v2
transforms = v2.Compose([
v2.RandomResizedCrop(size=(224, 224), antialias=True),
v2.RandomHorizontalFlip(p=0.5),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
In addition, you can make up your own custom transformation if you need it. Interested readers should check out this recent talk from Nicolas Hug who introduce the v2 API. A word of caution, at the time of writing this article this is a pretty recent API and most codebases still using the old one.
torch.utils.data.DataLoader
To understand how dataloading works we need to understand the Sampler and the Collator. In the following diagram, I try to summarize what is happening in the dataloader.
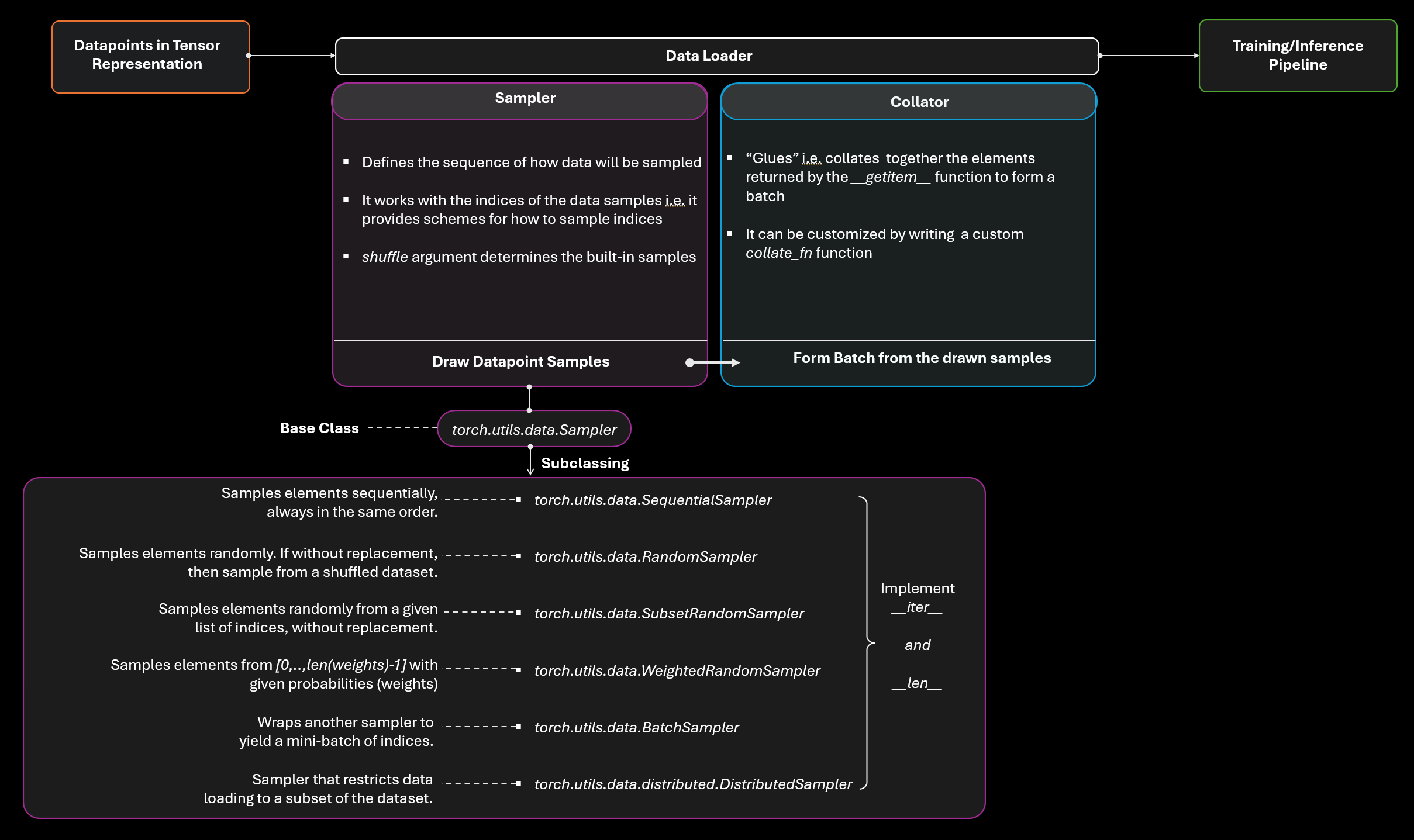
The dataloader is sitting between the raw data points and the training/inference pipeline. Its job is to sample data points to form a batch and hand over that batch to the training/inference pipeline. In addition, it needs to provide the functionality for multiprocessing and make the dataloading process as efficient as possible.
Sampler and BatchSampler
The job of the Sampler is to sample indices of data points according to a certain scheme.
Sampler and BatchSampler works with indices of the map-style dataset rather than working with the actual data points. Keep this in mind if sometimes I refer to actual data points for better clarity.
To implement a Sampler you need to do the following things:
- Inherit the
torch.utils.data.Samplerclass - Implement the
__iter__method and__len__method (the latter is not mandatory)
We can take a look at the SequentialSampler source code to get a feel for it:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class SequentialSampler(Sampler[int]):
r"""Samples elements sequentially, always in the same order.
Args:
data_source (Dataset): dataset to sample from
"""
data_source: Sized
def __init__(self, data_source: Sized) -> None:
self.data_source = data_source
def __iter__(self) -> Iterator[int]:
return iter(range(len(self.data_source)))
def __len__(self) -> int:
return len(self.data_source)
Take a close look at the __iter__ method which is just returning an iterator over the range of indices of the data samples. If you need a refresher on iterators take a look at this video. All the other Samplers including RandomSampler, SubsetRandomSampler, WeightedRandomSampler also return an iterator.
However, BatchSampler is completely different in behavior.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
class BatchSampler(Sampler[List[int]]):
def __init__(self, sampler: Union[Sampler[int], Iterable[int]], batch_size: int, drop_last: bool) -> None:
self.sampler = sampler
self.batch_size = batch_size
self.drop_last = drop_last
def __iter__(self) -> Iterator[List[int]]:
if self.drop_last:
sampler_iter = iter(self.sampler)
while True:
try:
batch = [next(sampler_iter) for _ in range(self.batch_size)]
yield batch
except StopIteration:
break
else:
batch = [0] * self.batch_size
idx_in_batch = 0
for idx in self.sampler:
batch[idx_in_batch] = idx
idx_in_batch += 1
if idx_in_batch == self.batch_size:
yield batch
idx_in_batch = 0
batch = [0] * self.batch_size
if idx_in_batch > 0:
yield batch[:idx_in_batch]
def __len__(self) -> int:
if self.drop_last:
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
I removed some code and comments so that it’s more clean. The __init__ method indicates the batch sampler only cares about sampler, batch_size and drop_last argument.
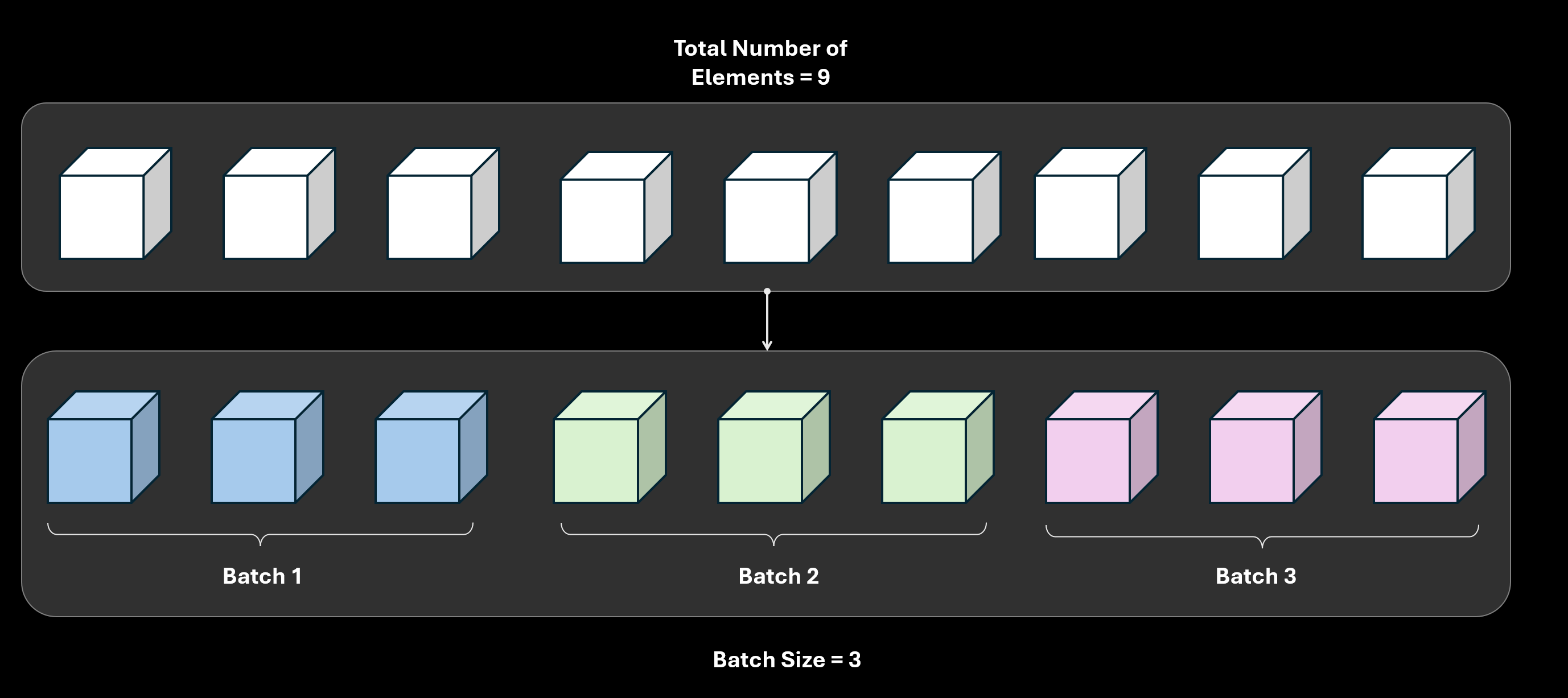
First, we need to understand the batch_size and drop_last parameters. batch_size means the number of elements in a single batch. Let’s take an example of $9$ elements and batch size of $3$. That means there are going to be $9/3=3$ batches and each batch will contain $3$ elements.
But what happens when the total number of elements is not divisible by the batch_size argument? Say there are a total of $10$ elements and the batch size is $3$.
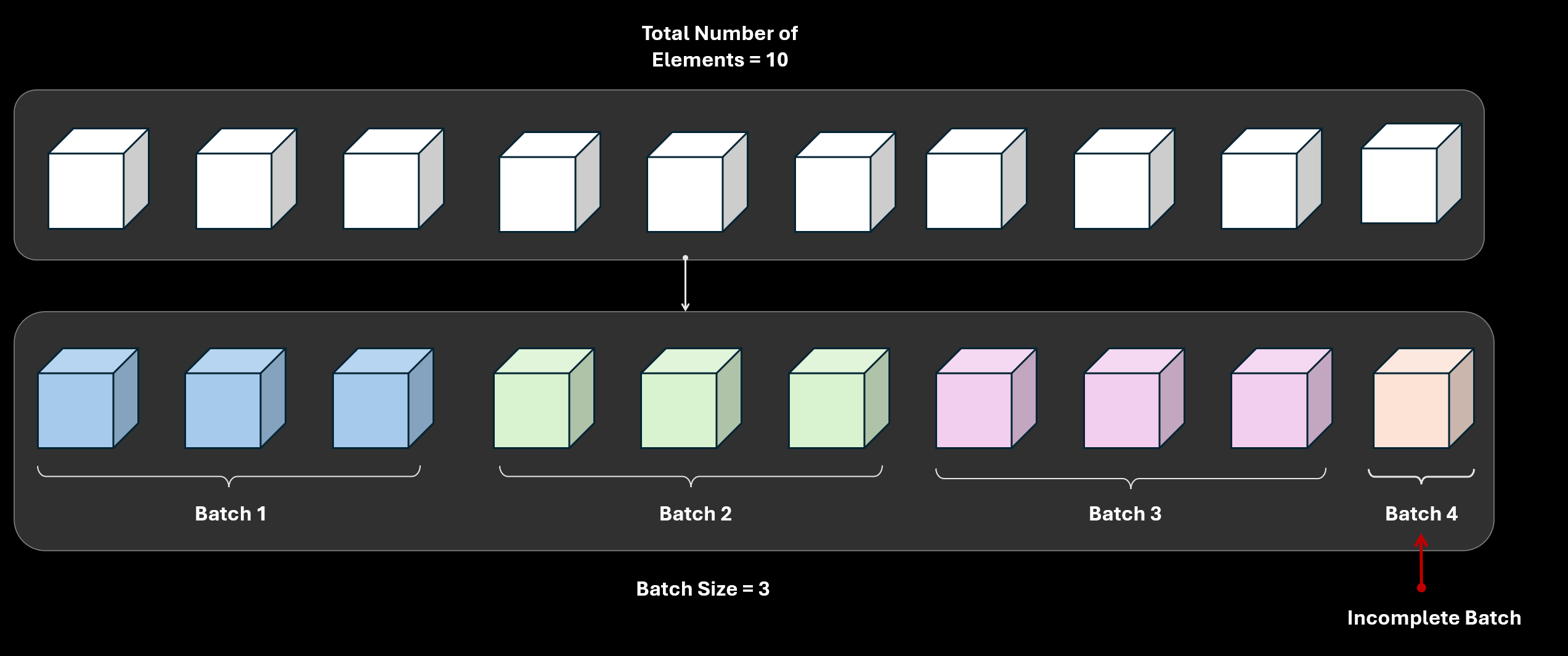
If drop_last=False (which is the default behavior), there will be a total of $4$ batches where the first $3$ batch will contain $3$ elements each. However, the last batch will contain only a single element.
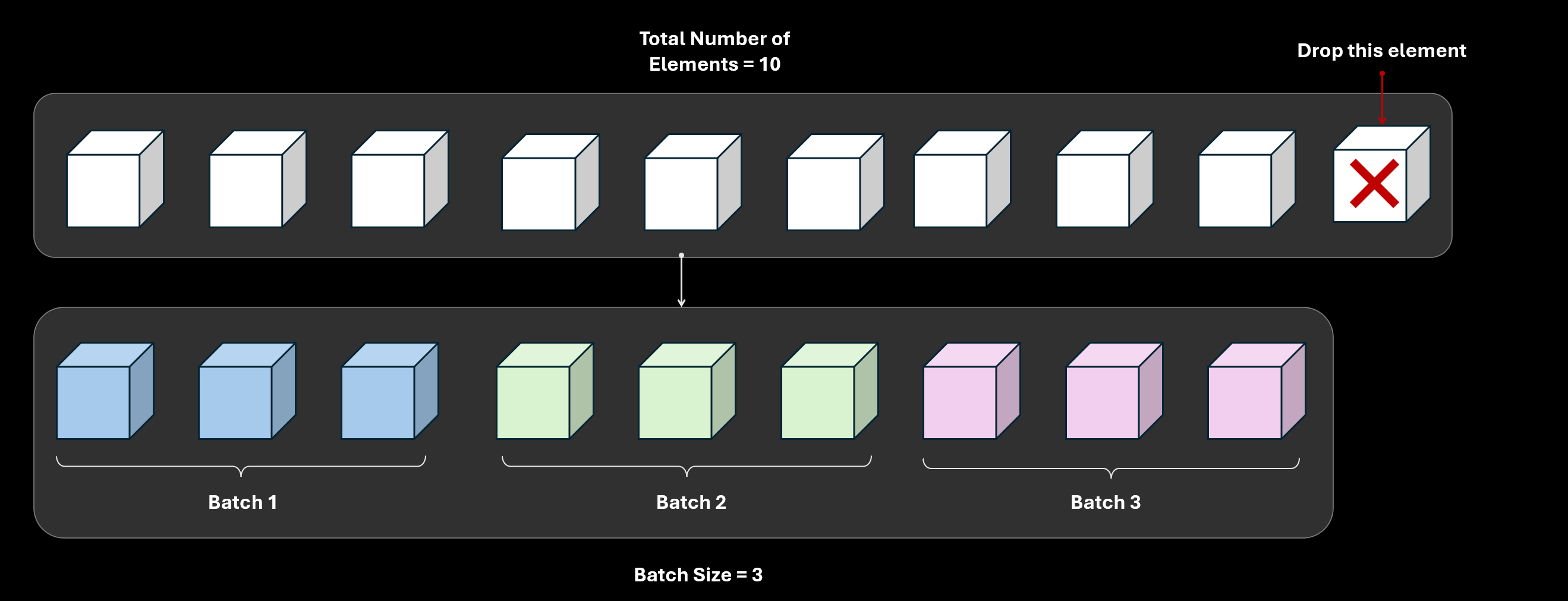
On the other hand if drop_last=True that means the last element will be dropped. More generally, some elements will be dropped so that the number of elements (after dropping) is completely divisible by the batch size.
After knowing this information, if you look at the __len__ method it makes complete sense.
1
2
3
4
5
6
def __len__(self) -> int:
if self.drop_last:
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
If drop_last is True then according to this example len(self.sampler) is equal to $10$ and self.batch_size=3. If floor division is performed then $10//3=3$ which is the number of batches.
If drop_last is False then according to this example, $(10+3-1)//3=4$ i.e. the number of batches is $4$.
Now, let’s shift our focus to the __iter__ method. Again to understand this you need to have a clear idea about Iterators and Generators in Python.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def __iter__(self) -> Iterator[List[int]]:
if self.drop_last:
sampler_iter = iter(self.sampler)
while True:
try:
batch = [next(sampler_iter) for _ in range(self.batch_size)]
yield batch
except StopIteration:
break
else:
batch = [0] * self.batch_size
idx_in_batch = 0
for idx in self.sampler:
batch[idx_in_batch] = idx
idx_in_batch += 1
if idx_in_batch == self.batch_size:
yield batch
idx_in_batch = 0
batch = [0] * self.batch_size
if idx_in_batch > 0:
yield batch[:idx_in_batch]
This can be broken down into two parts. If self.drop_last==True then
1
2
3
4
5
6
7
8
9
10
...
if self.drop_last:
sampler_iter = iter(self.sampler)
while True:
try:
batch = [next(sampler_iter) for _ in range(self.batch_size)]
yield batch
except StopIteration:
break
...
Notice that we are creating an iterator over self.sampler which is sample_iter. Then by using the next method inside the List comprehension we create the list of indices for a batch and by using yield we return that list of indices as an iterator.
Let’s look at the other case when self.drop_last==False
1
2
3
4
5
6
7
8
9
10
11
12
13
...
else:
batch = [0] * self.batch_size
idx_in_batch = 0
for idx in self.sampler:
batch[idx_in_batch] = idx
idx_in_batch += 1
if idx_in_batch == self.batch_size:
yield batch
idx_in_batch = 0
batch = [0] * self.batch_size
if idx_in_batch > 0:
yield batch[:idx_in_batch]
In this implementation, we create a zero-filled list with a length equal to the batch size. Then we keep inserting elements from the sampler into that list i.e. batch[idx_in_batch] = idx. When that list is completely filled we yield that batch and reset everything.
Finally, yield batch[:idx_in_batch] actually yields the incomplete batch.
Collator
The job of a collator is to form a batch. To get an intuition let’s take a look at the definition given in the documentation for torch.utils.data.default_collate()
Take in a batch of data and put the elements within the batch into a tensor with an additional outer dimension - batch size.
I am not going to go into the source code because it is way too complex due to its generalization capability to handle many many types of datasets.
However, we can take a look at the function signatures in the source code to get a feel for it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def collate_tensor_fn(batch, *, collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None):
...
def collate_numpy_array_fn(batch, *, collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None):
...
def collate_numpy_scalar_fn(batch, *, collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None):
...
def collate_float_fn(batch, *, collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None):
...
def collate_int_fn(batch, *, collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None):
...
def collate_str_fn(batch, *, collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None):
...
It is apparent that it is capable of handling different data types. The following is from the official documentation which clarifies a few more things.
For instance, if each data sample consists of a 3-channel image and an integral class label, i.e., each element of the dataset returns a tuple (image, class_index), the default collate_fn collates a list of such tuples into a single tuple of a batched image tensor and a batched class label Tensor. In particular, the default collate_fn has the following properties:
- It always prepends a new dimension as the batch dimension.
- It automatically converts NumPy arrays and Python numerical values into PyTorch Tensors.
- It preserves the data structure, e.g., if each sample is a dictionary, it outputs a dictionary with the same set of keys but batched Tensors as values (or lists if the values can not be converted into Tensors).
References
- https://pytorch.org/docs/stable/data.html